אני ממליץ על מאמרו של הנלי, & McNeil, משנת 1982 ' המשמעות והשימוש באזור תחת עקומת הפעלת מקלט (ROC)'.
דוגמה
יש להם את הטבלה הבאה של מצב המחלה ותוצאת הבדיקה (התואמת, למשל, את הסיכון המשוער ממודל לוגיסטי). המספר הראשון בצד ימין הוא מספר החולים ש אמיתי מצב המחלה 'נורמלי' והמספר השני הוא מספר החולים ש אמיתי מצב המחלה 'לא תקין':
(1) נורמלי בהחלט: 33/3
(2) כנראה נורמלי: 6/2
(3) מוטל בספק: 6/2
(4) כנראה לא תקין: 11/11
(5) בהחלט לא תקין: 2/33
כך שיש בסך הכל 58 חולים 'רגילים' ו- '51' חריגים. אנו רואים שכאשר המנבא הוא 1, 'נורמלי בהחלט', המטופל בדרך כלל תקין (נכון עבור 33 מתוך 36 המטופלים), וכאשר הוא 5, 'בהחלט לא תקין' המטופלים בדרך כלל חריגים (נכון עבור 33 מתוך 35 חולים), כך שהמנבא הגיוני. אך כיצד עלינו לשפוט מטופל עם הציון 2, 3 או 4? מה שאנו קובעים לניתוק שלנו לשפוט חולים כלא תקין או תקין, קובע את הרגישות והספציפיות של הבדיקה שהתקבלה.
רגישות וספציפיות
אנו יכולים לחשב את / em> רגישות וספציפיות לניתוקים שונים. (אני פשוט אכתוב מעתה ואילך 'רגישות' ו'ספציפיות ', ונותן לאופי המשוער של הערכים להיות מרומז.)
אם אנו בוחרים בניתוק שלנו כך שנסווג הכל em> המטופלים כלא תקינים, לא משנה מה אומרות תוצאות הבדיקה שלהם (כלומר, אנו בוחרים את הקיצוץ 1+), נקבל רגישות של 51/51 = 1. הספציפיות תהיה 0/58 = 0. לא נשמע כל כך טוב.
בסדר, אז בוא נבחר לנתק פחות קפדני. אנו מסווגים מטופלים כלא תקינים אם יש להם תוצאת בדיקה של 2 ומעלה. לאחר מכן אנו מתגעגעים ל -3 חולים לא תקינים ויש לנו רגישות של 48/51 = 0.94. אך יש לנו ספציפיות מוגברת בהרבה, של 33/58 = 0.57.
כעת אנו יכולים להמשיך בכך, בבחירת ניתוקים שונים (3, 4, 5,> 5). (במקרה האחרון לא נסווג חולים כלשהם כלא תקינים, גם אם הם בעלי ציון הבדיקה הגבוה ביותר האפשרי של 5.)
עקומת ROC
אם אנו עושים זאת עבור כל הניתוחים האפשריים, ועלילת הרגישות מול 1 פחות הספציפיות, נקבל את עקומת ROC. אנו יכולים להשתמש בקוד R הבא:
# Datanorm = rep (1: 5, times = c (33,6,6,11,2 )) abnorm = rep (1: 5, times = c (3,2,2,11,33)) testres = c (abnorm, norm) truestat = c (rep (1, אורך (abnorm)), rep (0 , אורך (נורמה))) # טבלת סיכום (טבלה I בעיתון) (tab = as.matrix (טבלה (truestat, testres)))
הפלט הוא:
testrestruestat 1 2 3 4 5 0 33 6 6 11 2 1 3 2 2 11 33
אנחנו יכולים לחשב שונים סטטיסטיקה:
(tot = colSums (tab)) # מספר חולים עם כל תוצאת בדיקה (truepos = unname (rev (cumsum (rev ()) לשונית [2,]))))) # מספר החיובי האמיתי (falsepos = unname (rev (cumsum (rev (tab [1,])))) # מספר החיובי השגוי (totpos = sum (tab [2, ])) # המספר הכולל של תוצאות חיוביות (מספר אחד) (totneg = סכום (כרטיסייה [1,])) # המספר הכולל שליליות (מספר אחד) (sens = truepos / totpos) # רגישות (חלק חיובי נכון) (omspec = falsepos / totneg) # 1 - ספציפיות (חיובי שווא) sens = c (sens, 0); omspec = c (omspec, 0) # מספרים כאשר אנו מסווגים הכל כרגיל
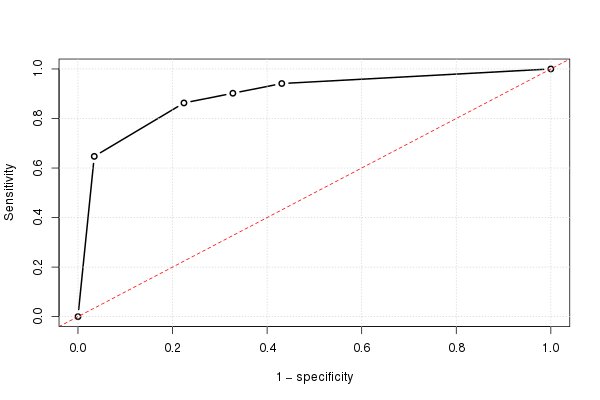
ובאמצעות זה נוכל לשרטט את עקומת ה- ROC (המשוערת):
עלילה (omspec, sens, type =" b ", xlim = c (0,1), ylim = c (0,1), lwd = 2, xlab =" 1 - ספציפיות ", ylab =" רגישות ") # אולי עם xaxs =" i "רשת () מוטה (0,1, col =" אדום ", lty = 2)
חישוב ידני של ה- AUC
אנו יכולים לחשב בקלות רבה את השטח מתחת לעקומת ROC, באמצעות הנוסחה לאזור הטרפז:
height = (sens [ -1] + sens [-length (sens)]) / 2width = -diff (omspec) # = diff (rev (omspec)) סכום (גובה * רוחב)
התוצאה היא 0.8931711.
מדד קונקורדנציה
ניתן לראות את ה- AUC גם כמדד קונקורדנציה. אם ניקח את כל ה זוגות האפשריים של המטופלים כאשר אחד מהם תקין והשני אינו תקין, נוכל לחשב באיזו תדירות זה הוא לא נורמלי בעל תוצאת הבדיקה הגבוהה ביותר (למראה 'לא נורמלי ביותר') (אם יש להם אותו ערך, אנו סופרים שזה 'חצי ניצחון'):
o = חיצוני (חריג, נורמה, "-") ממוצע ((o>0) + .5 * (o == 0))
התשובה היא שוב 0.8931711, השטח מתחת לעיקול ROC. זה תמיד יהיה המקרה.
מבט גרפי על קונקורדנציה
כפי שציין הראל בתשובתו, יש לכך גם פרשנות גרפית. בואו נתווה את ציון הבדיקה (אומדן הסיכון) על ציר ה y ומצב המחלה האמיתי על ציר ה x (כאן עם כמה עצבנות, כדי להראות נקודות חופפות):
עלילה (ריצוד (truestat, .2), ריצוד (testres, .8), las = 1, xlab = "מצב מחלה אמיתי", ylab = "ציון מבחן")
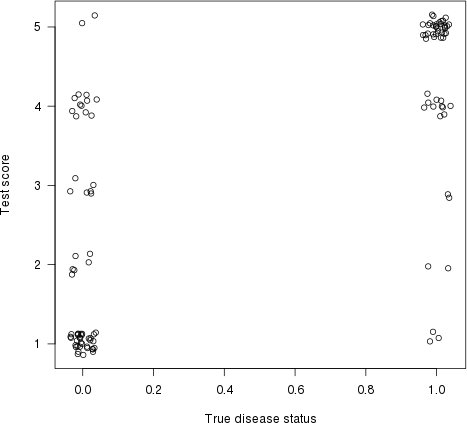
בואו נשרטט קו בין כל נקודה משמאל (מטופל 'רגיל') לכל נקודה על ימין (חולה 'לא תקין'). שיעור הקווים בעלי שיפוע חיובי (כלומר, חלקם של הקונקורדנטיות זוגות) הוא אינדקס הקונקורדנציה (קווים שטוחים נחשבים '50% קונקורדנציה ').
קצת קשה לדמיין את השורות בפועל לדוגמא זו, בגלל מספר הקשרים (ציון סיכון שווה), אך עם קצת רטט ושקיפות אנו יכולים להשיג עלילה סבירה:
d = cbind (x_norm = 0, x_abnorm = 1, expand.grid (y_norm = norm, y_abnorm = abnorm)) ספרייה (ggplot2)
ggplot (d, aes (x = x_norm, xend = x_abnorm, y = y_norm, yend = y_abnorm)) + geom_segment (color = "# ff000006", position = position_jitter (רוחב = 0, גובה = .1)) + xlab ( "מצב מחלה אמיתי") + ylab ("בדוק \ nscore") + theme_light () + theme (axis.title.y = element_text (angle = 0)) 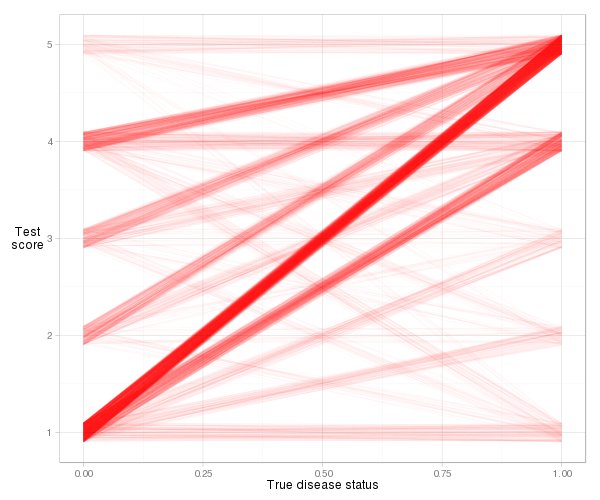
אנו רואים שרוב הקווים נוטים כלפי מעלה, כך שמדד הקונקורדנציה יהיה גבוה. אנו רואים גם את התרומה למדד מכל סוג של זוג תצפיות. רוב זה מגיע מחולים רגילים עם ציון סיכון של 1 יחד עם חולים לא תקינים עם ציון סיכון של 5 (1-5 זוגות), אך די הרבה מגיע גם מ- 1-4 זוגות ו- 4-5 זוגות. וקל מאוד לחשב את אינדקס הקונקורדנציה בפועל על סמך הגדרת השיפוע:
d = transform (d, slope = (y_norm-y_abnorm) / (x_norm-x_abnorm)) ממוצע ((d $ slope > 0) + .5 * (d $ slope == 0))
התשובה היא שוב 0.8931711, כלומר AUC.
מבחן Wilcoxon – Mann – Whitney
קיים קשר הדוק בין מדד הקונקורדנציה לבין מבחן Wilcoxon – Mann – Whitney. למעשה, האחרון בודק אם ההסתברות לקונקורדנציה (כלומר, זה החולה הלא תקין בזוג אקראי נורמלי – לא תקין שתהיה לו תוצאת הבדיקה הכי "לא תקינה") היא בדיוק 0.5. ונתון הבדיקה שלה הוא רק שינוי פשוט של ההסתברות הקונקורדנטית המשוערת:
> (wi = wilcox.test (abnorm, norm)) דרגת Wilcoxon מבחן סכום עם נתוני תיקון המשכיות: חריג ונורמה W = 2642, p-value = 1.944e-13 השערה אלטרנטיבית: שינוי מיקום אמיתי אינו שווה ל- 0
נתון הבדיקה ( W = 2642 ) מונה את מספר הזוגות התואמים. אם נחלק אותו למספר הזוגות האפשריים, נקבל מספר מוכר:
w = wi $ statisticw / (length (abnorm) * length (נורמה))
כן, זה 0.8931711, השטח שמתחת לעיקול ה- ROC.
דרכים קלות יותר לחישוב ה- AUC (ב- R)
אבל בואו נעשה לנו חיים קלים יותר. ישנן חבילות שונות המחושבות עבורנו את ה- AUC באופן אוטומטי.
חבילת Epi
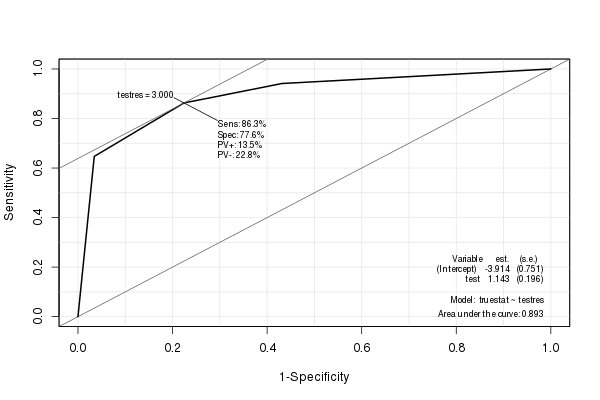
חבילת Epi יוצרת עקומת ROC יפה עם נתונים סטטיסטיים שונים (כולל AUC) מוטבע:
ספרייה (Epi) ROC (testres, truestat) # נסה גם להוסיף plot = "sp"
חבילת pROC
אני גם אוהב את החבילה pROC מכיוון שהיא יכולה להחליק את אומדן ה- ROC (ולחשב AUC הערכה על סמך ה- ROC המוחלק):
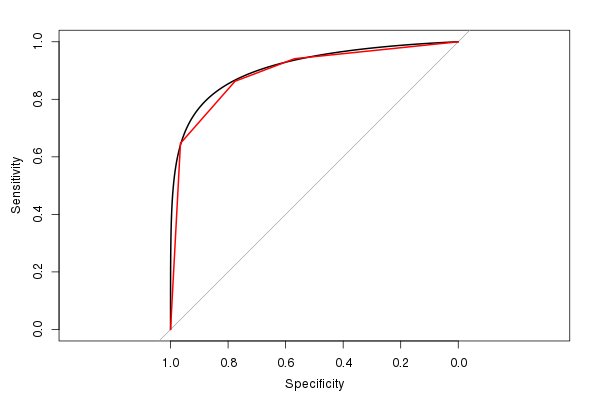
(הקו האדום הוא ה- ROC המקורי, והקו השחור הוא ה- ROC המוחלק. שימו לב גם לברירת המחדל 1: 1 יחס הגובה-רוחב. זה הגיוני להשתמש בזה, מכיוון שגם לרגישות וגם לספציפיות יש טווח 0-1.)
ה- AUC המשוער מ- מוחלק ROC הוא 0.9107, בדומה ל , אך מעט גדול יותר מ- AUC מ- ROC הלא מוחלק (אם מסתכלים על הדמות, תוכלו לראות בקלות מדוע היא גדולה יותר). (אם כי באמת יש לנו מעט מדי ערכי תוצאות בדיקה אפשריים בכדי לחשב AUC חלק).
חבילת ה- rms
חבילת ה- rms של הראל יכולה לחשב קשורים שונים סטטיסטיקה של קונקורדנציה באמצעות הפונקציה rcorr.cens () . C אינדקס בפלט שלו הוא AUC:
ספריית > (rms) > rcorr.cens (testres, truestat ] [1] אינדקס C 0.8931711
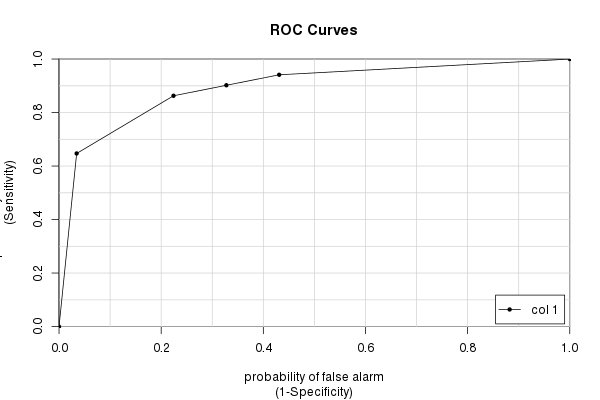
חבילת caTools
לבסוף, יש לנו את החבילה caTools ואת colAUC () שלה פונקציה . יש לו כמה יתרונות על פני חבילות אחרות (בעיקר מהירות ויכולת לעבוד עם נתונים רב מימדיים - ראה ? ColAUC ) שיכולות לפעמים להועיל. אבל כמובן שזה נותן את אותה התשובה כמו שחישבנו שוב ושוב:
ספרייה (caTools)
colAUC (testres, truestat, plotROC = TRUE) [, 1] 0 לעומת 1 0.8931711
מילים אחרונות
רבות נראה שאנשים חושבים שה- AUC אומר לנו עד כמה מבחן 'טוב'. ויש אנשים שחושבים ש- AUC הוא ההסתברות שהבדיקה תסווג נכון את המטופל. זה לא . כפי שניתן לראות מהדוגמה והחישובים הנ"ל, ה- AUC מספר לנו משהו על משפחה של בדיקות, בדיקה אחת לכל ניתוק אפשרי.
וה- AUC מחושב על סמך קיצוצים שאף פעם לא ישתמשו בפועל. מדוע עלינו לדאוג לרגישות ולספציפיות של ערכי ניתוק 'חסרי טעם'? ובכל זאת, על זה מבוסס ה- AUC (באופן חלקי). (כמובן, אם ה- AUC יהיה מאוד קרוב ל -1, כמעט לכל מבחן אפשרי יהיה כוח מפלה רב, וכולנו נשמח מאוד.)
הנורמלי האקראי פרשנות זוגית לא תקינה של ה- AUC היא נחמדה (וניתן להרחיב אותה, למשל, למודלים של הישרדות, שם אנו רואים אם מדובר באדם עם הסיכון הגבוה ביותר (היחסי) שמת בתחילת הדרך). אבל לעולם לא ישתמש בזה בפועל. זה מקרה נדיר שבו אדם ש יודע שיש לו אחד בריא ו אדם חולה, לא יודע איזה אדם הוא החולה, וחייב להחליט במי מהם לטפל. (בכל מקרה, ההחלטה קלה; לטפל בזה עם הסיכון המשוער הגבוה ביותר.)
אז אני חושב שלימוד ה עקומת ROC בפועל יהיה שימושי יותר מסתם להסתכל על מדד סיכום AUC. ואם אתה משתמש ב- ROC יחד עם (הערכות של) ה עלויות של תוצאות חיוביות שגויות ושליליות כוזבות, יחד עם שיעורי הבסיס של מה שאתה לומד, אתה יכול להגיע לאנשהו.
שים לב גם ש- AUC מודד רק אפליה , ולא כיול. כלומר, זה מודד אם אתה יכול להבחין בין שני אנשים (אחד חולה ואחד בריא), על סמך ציון הסיכון. לשם כך, הוא מסתכל רק על ערכי סיכון יחסיים (או מדרגים, אם תרצו, עיין בפרשנות הבדיקה של Wilcoxon – Mann – Whitney), ולא על המוחלט ש אתה צריך למשל, אם אתה מחלק כל הערכת סיכונים מהמודל הלוגיסטי שלך ב -2, תקבל בדיוק אותו AUC (ו- ROC).
בעת הערכת מודל סיכון, כיול הוא גם מאוד חשוב. כדי לבחון זאת, תסתכל על כל החולים עם ציון הסיכון של סביב, למשל, 0.7, ותראה אם כ- 70% מאלה אכן היו חולים. עשו זאת לכל ציון סיכון אפשרי (אולי באמצעות איזושהי החלקה / רגרסיה מקומית). התווה את התוצאות, ותקבל מדד גרפי של כיול .
אם יש לך מודל עם כיול טוב ואפליה טובה, אז אתה להתחיל להיות מודל טוב. :)